Fine-tuning a large language model for automated code compliance of building regulations
Advanced Engineering Informatics 2025
- 1Department of Civil and Environmental Engineering, National University of Singapore
- 2Research and Innovation, NovaCITYNETS Pte.Ltd.
Abstract
In the Architecture, Engineering, and Construction (AEC) industry, the interpretation and conversion of building rules into a computer-processable format for automated compliance checking systems are crucial for improving the design process. Yet, current systems and research on rule interpretation either demand extensive and timeconsuming expert-induced intervention, or rely on hard-coded pattern matching with limited applicability. To address these limitations, this paper introduces BuildThemis, a framework integrating a large language model fine-tuned on a real-world rule interpretation dataset with a Retrieval-Augmented Generation (RAG) mechanism. BuildThemis serves as a code-assistance tool that delivers structured draft scripts that experts can readily refine. The RAG technique grounds the fine-tuned LLM using an external code knowledge base, achieving a higher CodeBERTScore compared to non-RAG code generation approaches. Results demonstrate that the BuildThemis framework enhances the rule interpretation process by capturing latent concepts within rule-script pairs across various codes of practice and generating semantically similar scripts compared to the reference scripts. This approach to automating rule interpretation emphasizes generalization and reusability of rules, enabling the efficient conversion of textual regulatory documents into computable formats.Addressing Qualitative Rules in Automated Code Compliance
Traditional NLP for ACC tends to rely on explicitly defined terms and NER-style extraction, which makes it ineffective for qualitative clauses with ambiguous interpretations; implicit assumptions (e.g., “shall be ventilated”, “overlooking”) often require expert knowledge, and cross-code context is hard to maintain without heavy manual pre-processing. To address this gap, we fine-tune an LLM on a domain-specific dataset spanning multiple Singapore codes of practice (Table 1), distinguishing quantitative rules that contain explicit numerical constraints from qualitative rules expressed descriptively. In the training set, 384/656 (58.54%) are quantitative and 272/656 (41.46%) are qualitative; the test set is similarly balanced.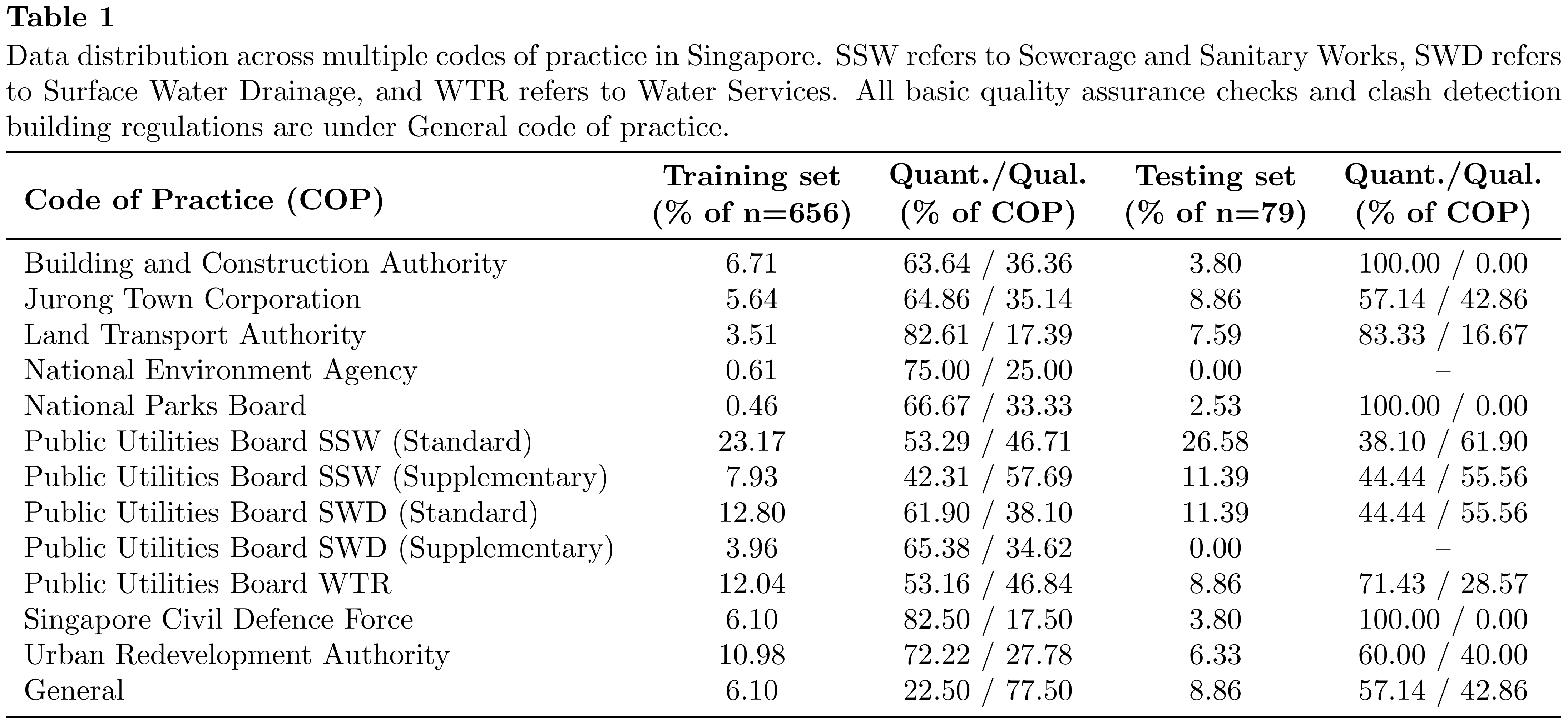
Fine-tuning Mistral 7B Instruct Model
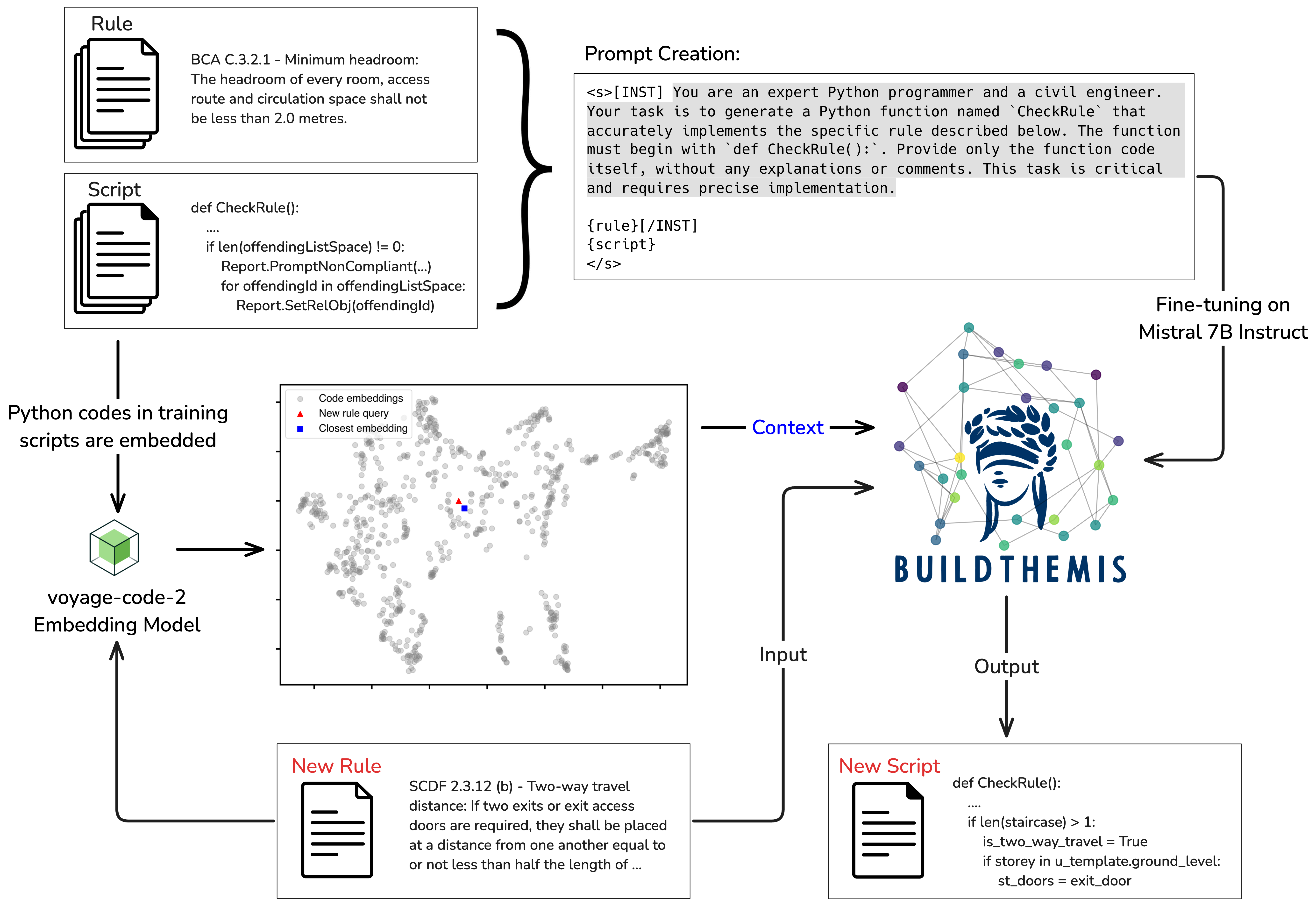
BuildThemis uses Mistral 7B Instruct v0.3 as its base model, fine-tuned via quantized low-rank adaptation (QLoRA) on 656 rule-script pairs from a real-world rule interpretation project spanning multiple Singapore codes of practice. During fine-tuning, prompt masking ensures the model focuses solely on learning the latent concepts between textual rules and their corresponding computer-processable scripts. At inference, Retrieval-Augmented Generation (RAG) is incorporated by embedding training scripts using voyage-code-2 and retrieving the most similar code as contextual input, guiding the LLM to generate more complete and accurate draft scripts for new rules.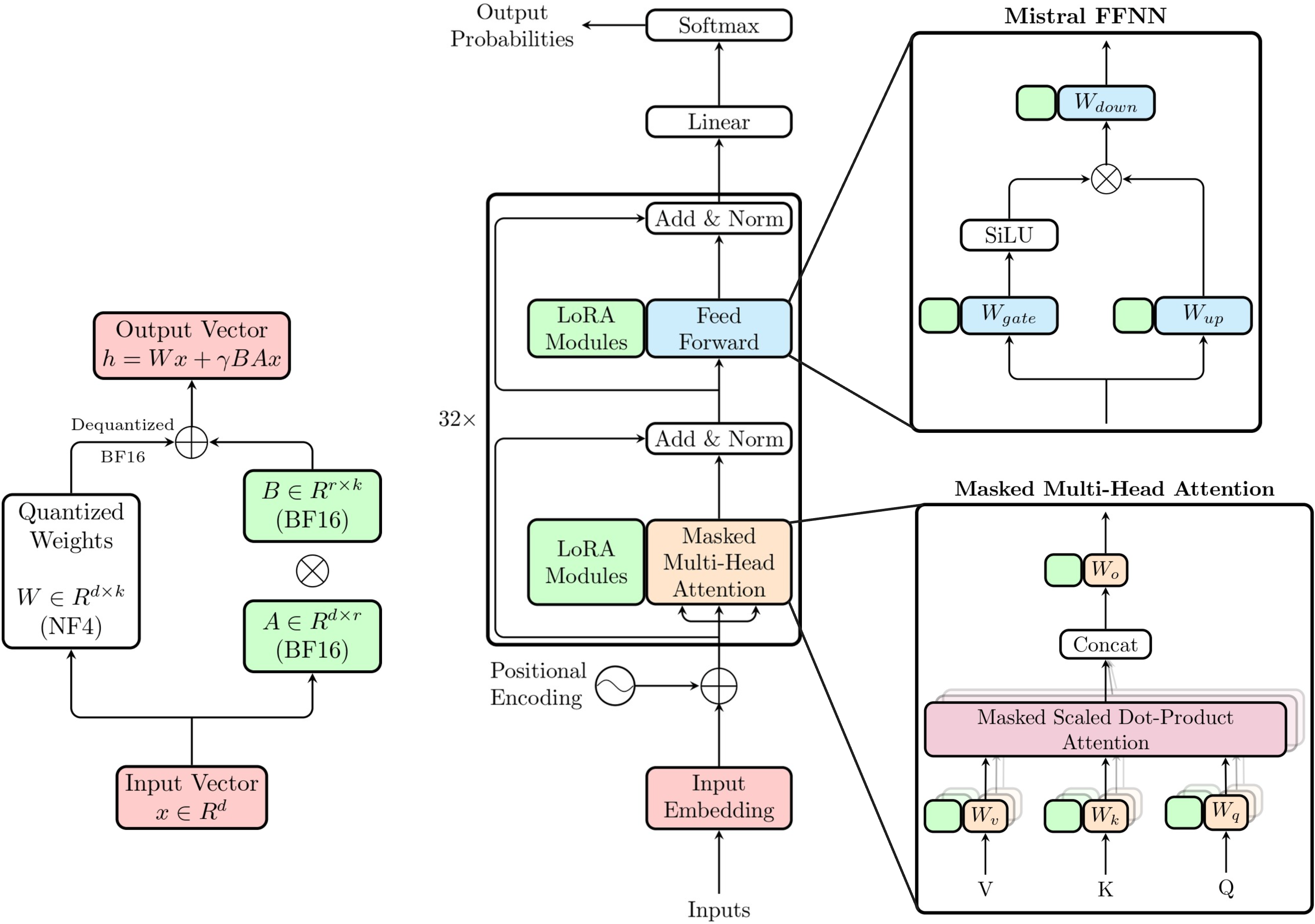
Results
Eight models (epochs 7–14) are evaluated on 79 test rule-script pairs using CodeBERTScore with both standard and RAG prompts. The model fine-tuned for 10 epochs achieves the highest mean F3 score under the standard prompt. Incorporating RAG with retrieved code context leads to statistically significant improvements in F3 scores across all epochs (Wilcoxon p-value ≤ 3.01 × 10-3), with the difference plot below showing that RAG particularly benefits scripts with initially low F3 scores.
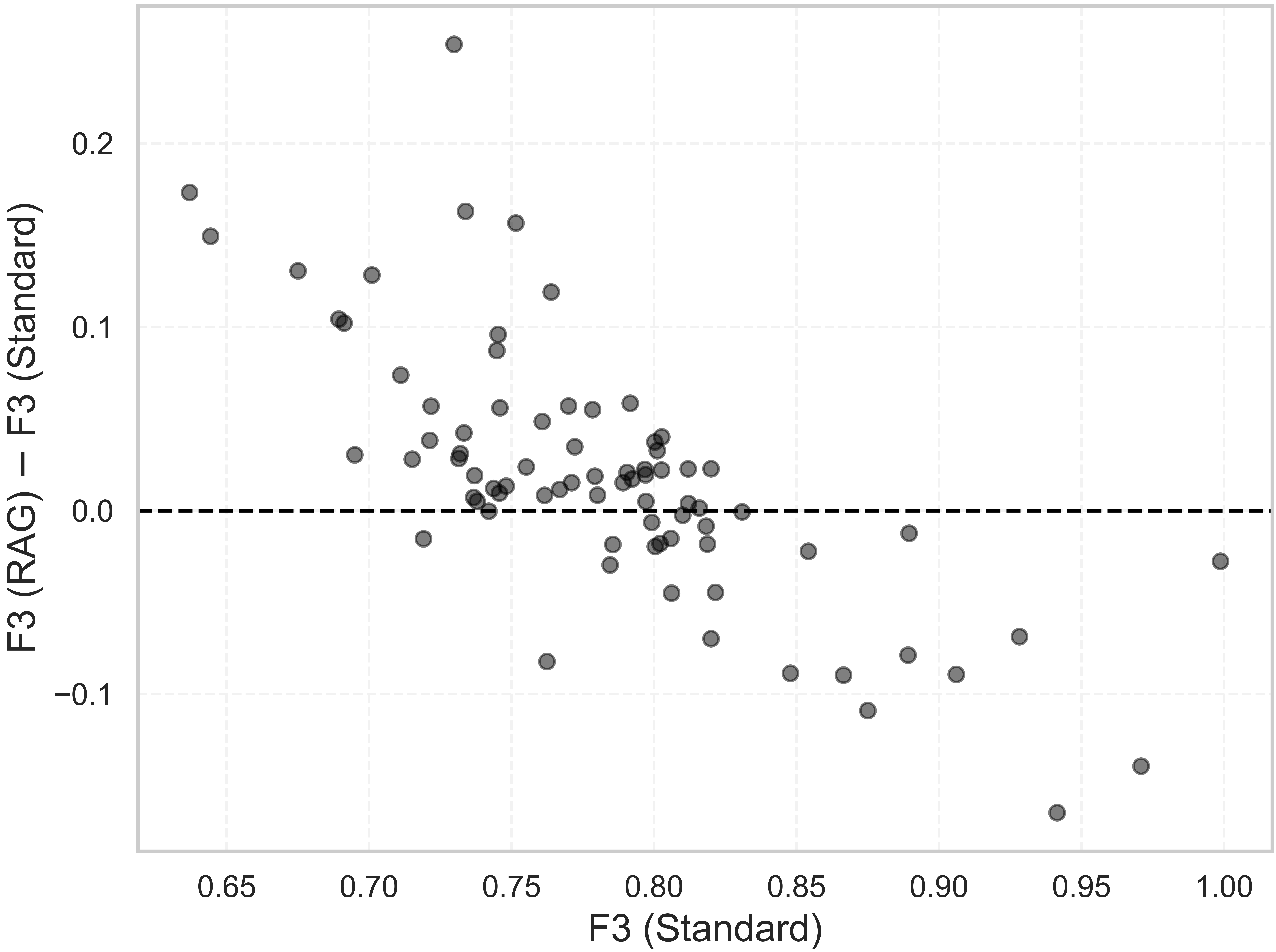
Effect of RAG on low F3 scores
This figure highlights the increase in F3 score achieved with the RAG prompt compared to the standard prompt at the 10th epoch, showing that the additional context in the RAG prompt significantly improves F3 scores, particularly for generated scripts with initially low F3 scores.Quantitative vs Qualitative Rule Types
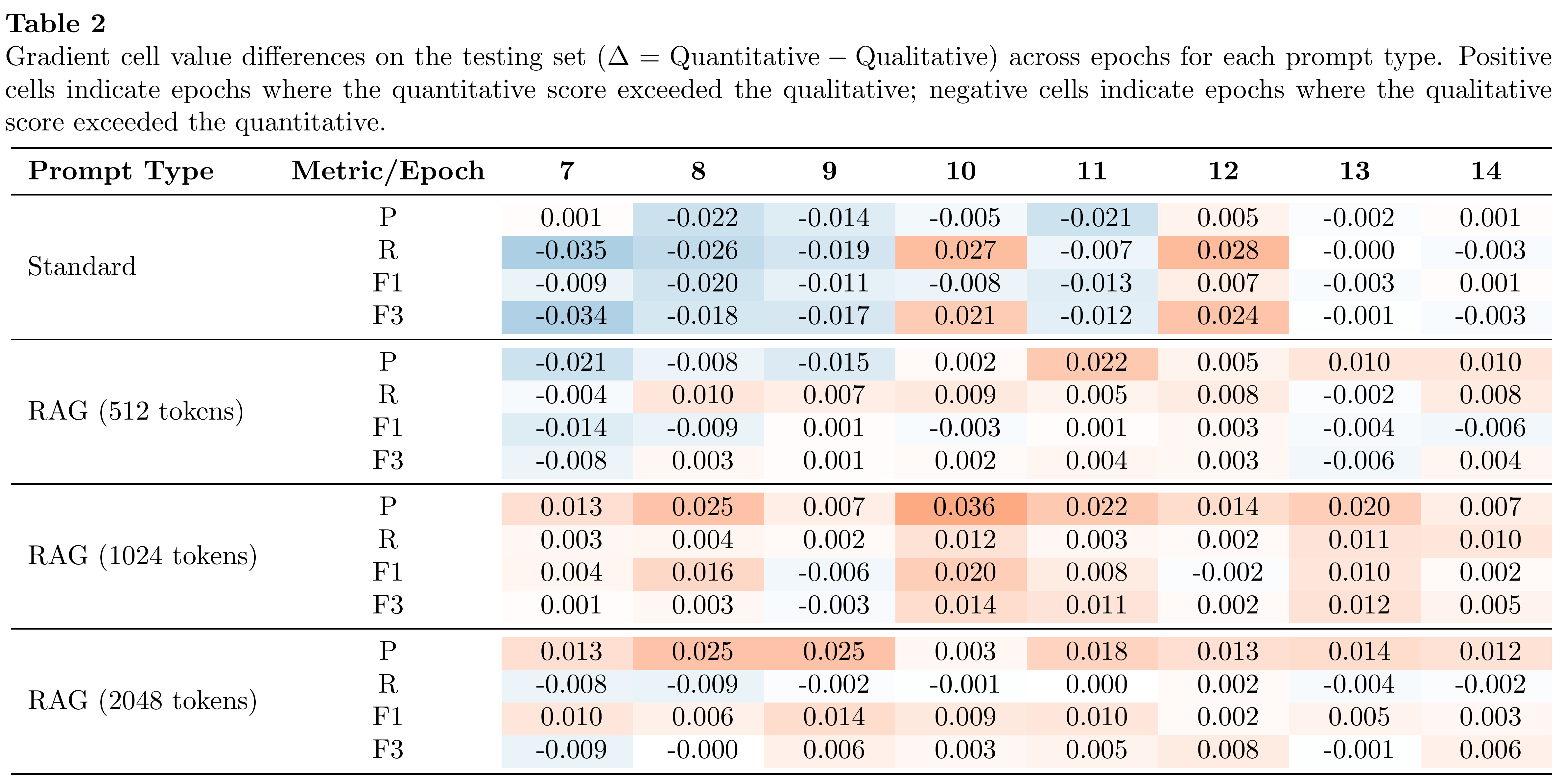
Table 2 shows the mean score difference (Δ = Quantitative − Qualitative) across epochs for each prompt type. Under the standard prompt, deltas remain within ±0.003 at higher epochs, indicating both rule types are generated almost indistinguishably. Incorporating RAG shifts precision toward quantitative rules—likely because retrieved context contains numerical anchors and structured cues that directly support quantitative rules—while the absolute gap between rule types remains orders of magnitude smaller than the overall improvement RAG yields on CodeBERTScore.